Don’t Start your Model from Scratch - Use Transfer Learning

Did you ever wish you could use one of your existing models as a starting point to solve a similar problem? Then you might want to try Transfer Learning. Transfer learning means to use or adapt an existing machine learning (ML) model for a new purpose and helps get you to a working model much faster.
A Transfer Learning approach is often preferable to building models from scratch because using existing models requires less training data and less computational time, which can also save you and your company money. Transfer learning also enables your models to perform better with limited amounts of data. With transfer learning, you can experiment with your pre-existing models in new ways, or repurpose many of the rich models available online today.
In this blog, we'll provide a brief introduction/refresher on the fundamentals of transfer learning, and show how you can easily accomplish transfer learning in PerceptiLabs today. And as we are constantly expanding PerceptiLabs' functionality to encompass more of the ML modeling process, we'll be adding additional transfer learning functionality so that you can get to a new model, even faster.
A Basic Domain of Knowledge
In transfer learning you typically deal with tasks and domains. A task refers to something that is to be accomplished (e.g., image recognition, object segmentation, etc.), while domain refers to the general category of problem being solved (e.g., identifying images of hand-written digits, finding anomalies in textiles, etc.). A domain shift occurs when a model or algorithm that was trained on data from one domain must then work on data from another domain. A source refers to the domain (e.g., model and data) from which learning is being transferred, while a target refers to the domain to which learning is being transferred to.
There are two general types of transfer learning to consider:
- First up is Inductive Transfer Learning (inductive learning) which is what most people think of when learning about transfer learning. Here the source and target domains are the same, but the tasks are different. With inductive learning, you build a model where any new data point can be predicted, and so the inductive biases of the source domain are used to improve the target task. In simpler terms, inductive learning uses a pre-trained model pretty much as is on a labelled training dataset, when you know that you can reliably predict/classify new data points which haven't yet been encountered on the test data set.
- On the other hand, there is Transductive Transfer Learning (transductive learning) where the source and target tasks are similar but the domains differ, although label data is available in the source domain. Here, both the training and test data are used to build the model. With this approach the training set is used to predict labels for the test dataset. When unknown data points are encountered in the test dataset, patterns and other information from the test data are used to learn how to predict their labels, which requires that the whole algorithm be retrained. Due to this retraining, transductive learning is generally more computationally expensive than inductive learning.
General Process
The general process for transfer learning involves removing the classifier from the source model, adding a new classifier for the target model, and fine tuning the model. The layers of the model containing the weights, known as the convolutional base for the image processing domain, may then be trained. You can retrain all of the layers in the convolutional base, retrain only some of them (where untrained layers are considered frozen), or leave all layers as is (sometimes called freezing the convolutional base). These strategies are depicted in Figure 1:
When you might choose each of these strategies is outlined below in Table 1:
Training Strategy | Use When: |
Train the whole model (convolutional base and classifier)
| You have a large target dataset that differs from that used to pre-train the source model (different source and target domain). |
Train most of the convolutional base layers and the classifier.
| You have a large target dataset that is similar to that used to pre-train the model (similar Domain). |
Train some of the convolutional base layers and the classifier.
| You have a small dataset that differs from that used to pre-train the model. |
Freeze the convolution base and train the classifier only.
| You have a small dataset that is similar to that used to pre-train the model. |
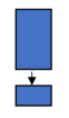
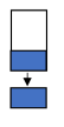
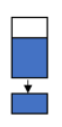
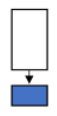
Table 1: Considerations for Freezing or Retraining some or all of the Convolutional Base.
The degree to which you retrain the convolutional base will depend on what the source model is capable of identifying (e.g., feature maps) and the requirements of your target task. Here are a few aspects of models that can be transferred using transfer learning:
- Instance Transfer: reuse certain parts or instances of the domain data in conjunction with labels from the target domain.
- Parameter Transfer: share parameters or a distribution of hyperparameters.
- Relational Knowledge: transfer relations between data points.
Consider for example, that you have a pre-trained model that can identify features of anomalies in materials like holes, cuts, and tears, and that it has been trained on images of textiles. You might then want to retrain this model to identify anomalies in another type of material (e.g., metal sheets) by taking advantage of the fact that the model can already identify common anomaly features. The model can be retrained by unfreezing some or all of the existing convolution base and retraining it on images of metal sheets, while a new classifier is retrained using labels associated with these new images.
Note that the convolutional base can consist of just about any sort of model architecture. Common examples used in image processing include various Convolution Neural Networks (CNNs), Generative Adversarial Networks (GANs), and many others.
Seeing into the Blackbox With PerceptiLabs
As beneficial as transfer learning is, it can be somewhat of a blackbox. For example, the following code from Keras, which uses pre-trained models available as part of Keras Applications, shows a typical transfer workflow:
$ Instantiate a base model with pre-trained weights.
base_model = keras.applications.Xception(
weights='imagenet', # Load weights pre-trained on ImageNet.
input_shape=(150, 150, 3),
include_top=False) # Do not include the ImageNet classifier at the top.
# freeze the base model.
base_model.trainable = False
# Create a new model on top.
inputs = keras.Input(shape=(150, 150, 3))
# We make sure that the base_model is running in inference mode here,
# by passing `training=False`. This is important for fine-tuning, as you will
# learn in a few paragraphs.
x = base_model(inputs, training=False)
# Convert features of shape `base_model.output_shape[1:]` to vectors
x = keras.layers.GlobalAveragePooling2D()(x)
# A Dense classifier with a single unit (binary classification)
outputs = keras.layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
# Train the model on new data.
model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.BinaryAccuracy()])
model.fit(new_dataset, epochs=20, callbacks=..., validation_data=...)From a quick glance of the code, it can be difficult to understand the architecture and it's not obvious if the full model is loaded or if the last few layers of the model are excluded. In addition, there are no visualizations to gain insight into how the data is transformed or what sort of predictions are being generated.
However, all is not lost.
You can use PerceptiLabs to gain more insight by embedding the Keras code that creates a model into PerceptiLabs' Custom component. In the example below, we show how a Custom component invokes tf.keras.applications.MobileNetV2() to get a pre-trained MobileNet v2 model, loaded with ImageNet weights:
In this example, the convolutional base is frozen (because ImageNet weights are being used) while the classifier is replaced (via a new Dense component) and fed with new label data that is first one-hot encoded to remove label ordinality. By using PerceptiLabs, you gain the ability to split the convolutional base and label training, and can visualize the transformed data and predictions. This in turn means you can more quickly understand what the model is doing and how you might need to retrain it.
For similar models, you can decide how much of the convolutional base to retrain by using the various Keras Application APIs available. For more information check out the examples in this article.
If you're interested in trying out this model in PerceptiLabs, we've made this model available at this GitHub repo.
Conclusion
Transfer learning is becoming a common and preferred method to create a new ML model. It allows ML practitioners to get to a working model much faster, and to experiment with existing models in different ways. And by understanding the domains and tasks of the source and targets models, ML practitioners can best determine how to retrain models during transfer learning.
You can use PerceptiLabs' Custom component in conjunction with pre-trained models like those from Keras Applications for transfer learning, but stay tuned as we add new functionality to support transfer learning in additional ways. And if you've come up with other clever ways for transfer learning that you think would work well in PerceptiLabs, be sure to contact us and let us know, or add your ideas to the forums.