Five GANs for Better Image Processing
Machine learning practitioners are increasingly turning to the power of generative adversarial networks (GANs) for image processing. Applications that really benefit from using GANs include: generating art and photos from text-based descriptions, upscaling images, transferring images across domains (e.g., changing day time scenes to night time), and many others. In order to achieve such results, a number of enhanced GAN architectures have been devised, with their own unique features for solving specific image processing problems.
We’ve chosen to take at a closer look at these five GANs making headlines today because they provide a wide gamut of functionality ranging from upscaling images to creating entirely new images from text-based descriptions:
If you need a quick refresher on GANs, check out our blog Exploring Generative Adversarial Networks, where we reviewed how a GAN trains two neural networks: the generator and discriminator that learn to generate increasingly realistic images while improving on its ability to classify images as real or fake.
Conditional GAN
A challenge with standard GANs is the inability to control the types of images generated. The generator simply starts with random noise, and repeatedly creates images which hopefully tend towards representing the training images over time.
A Conditional GAN (cGAN), solves this by leveraging additional information such as label data (aka class labels). This can also result in more stable or faster training, while potentially increasing the quality of generated images. For example, a cGAN presented with images of different types of mushrooms along with labels, can be trained to generate and discriminate only those mushrooms which are ready to pick . The resulting model could then be used as the basis for computer vision in an industrial robot programmed to find and pick mushrooms. Without such a condition, a standard GAN (sometimes called an unconditional GAN) simply relies on mapping the data in the latent space to that of the generated images.
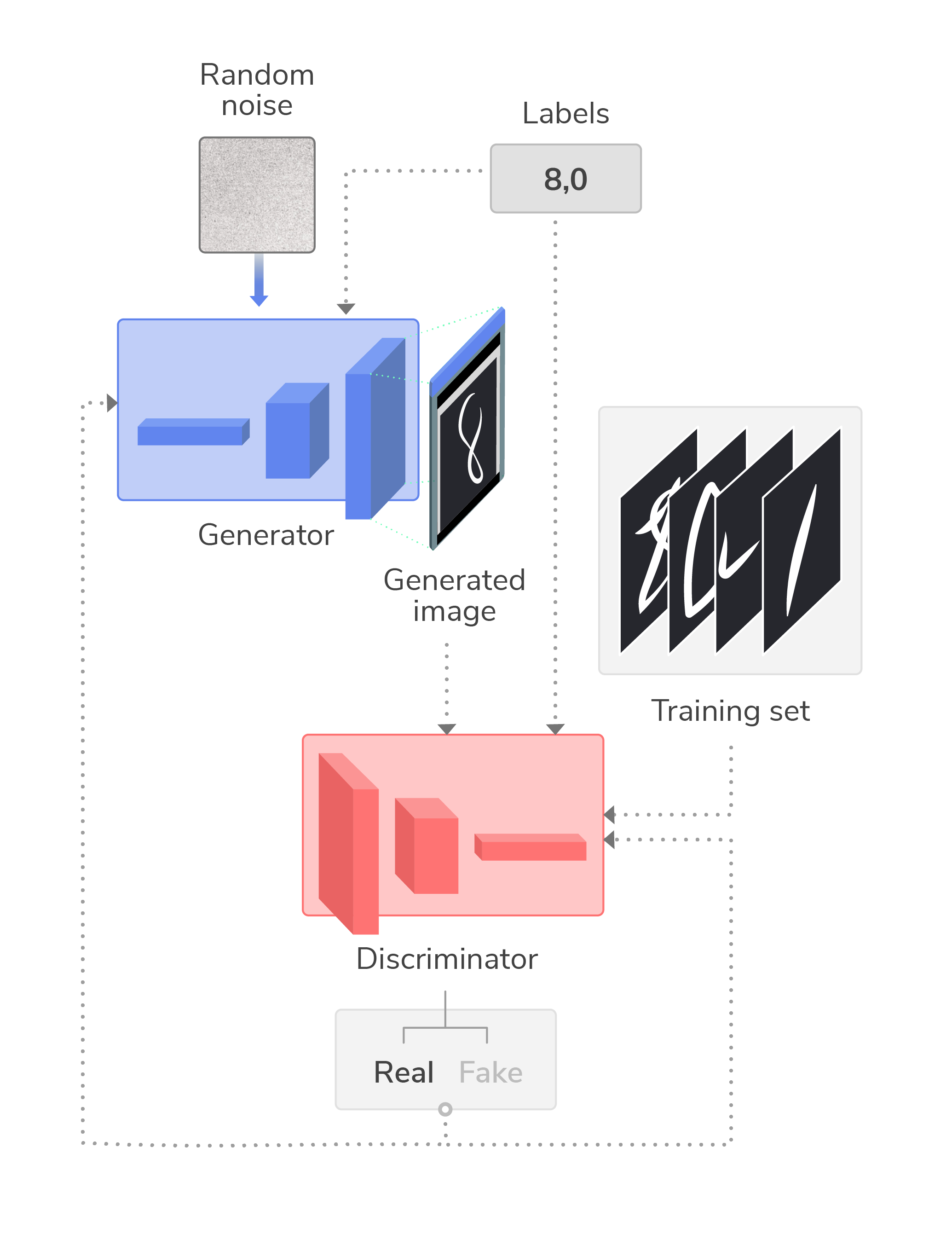
There are different approaches to implementing cGANs, but one approach is to condition both the discriminator and generator by inputting the class labels to both. The following example shows a standard GAN for generating images of handwritten digits, that is enhanced with label data to generate only images of the numbers 8 and 0:
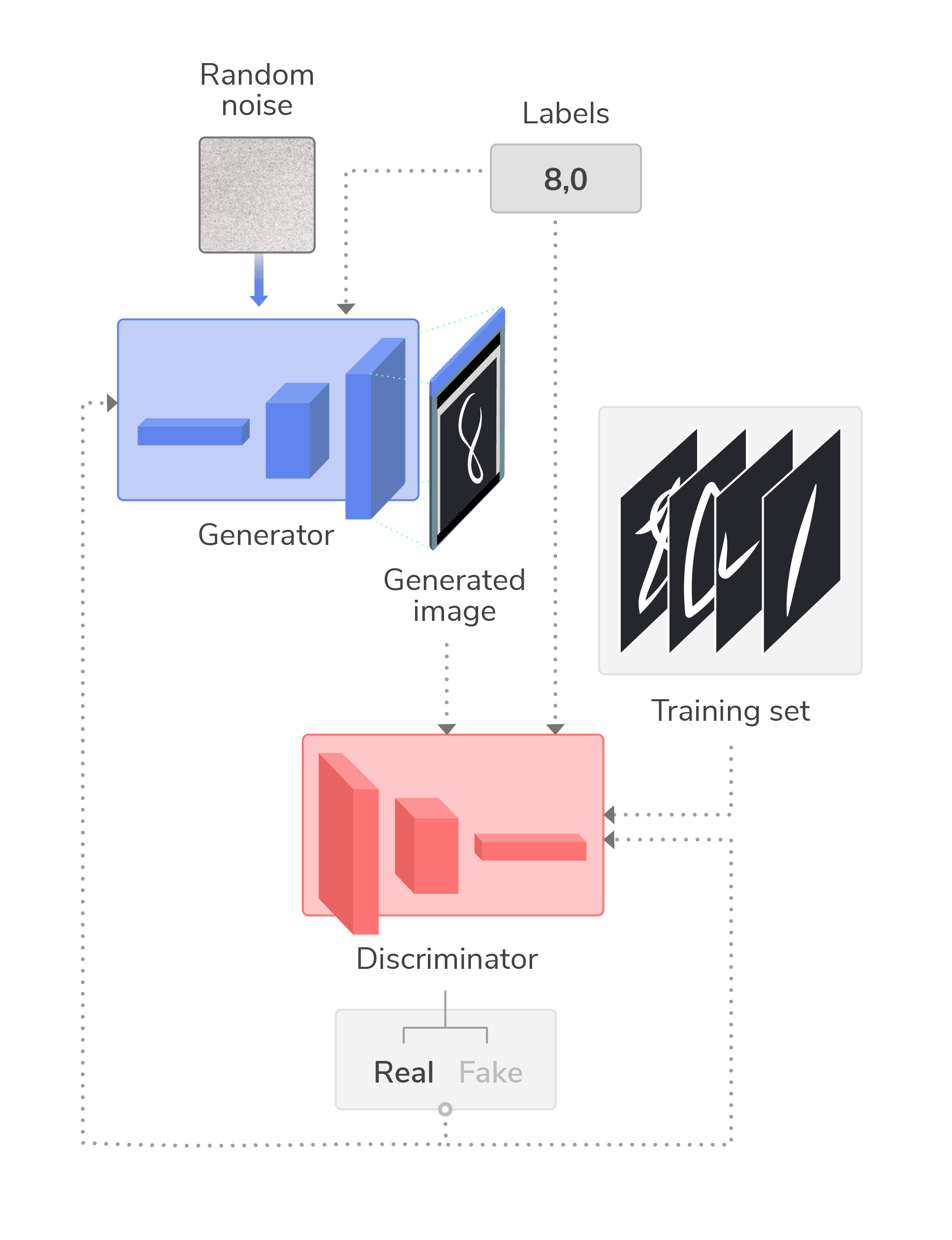
Here, labels can be one-hot encoded to remove ordinality and then input to both the discriminator and generator as additional layers, where they are then concatenated with their respective image inputs (i.e., concatenated with noise for the generator, and with the training set for the generator). Thus, both of the neural networks are conditioned on image class labels during training.
Summary: Use a cGAN when you need to control what gets generated (e.g., to generate a subset of the training data).
Stacked GAN
Wouldn't it cool if we could just ask a computer to draw a picture for us? Well, that was the inspiration behind the Stacked GAN (StackGAN), described in the paper StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks.
In the paper, the authors describe the StackGAN as basically a two-stage sketch-refinement process, similar to that used by painters where general elements are first drawn and then later refined:
Stage-I GAN: it sketches the primitive shape and basic colors of the object conditioned on the given text description, and draws the background layout from a random noise vector, yielding a low-resolution image.
Stage-II GAN: it corrects defects in the low-resolution image from Stage-I and completes details of the object by reading the text description again, producing a high resolution photo-realistic image.
The authors provide the following overview of their model's architecture:
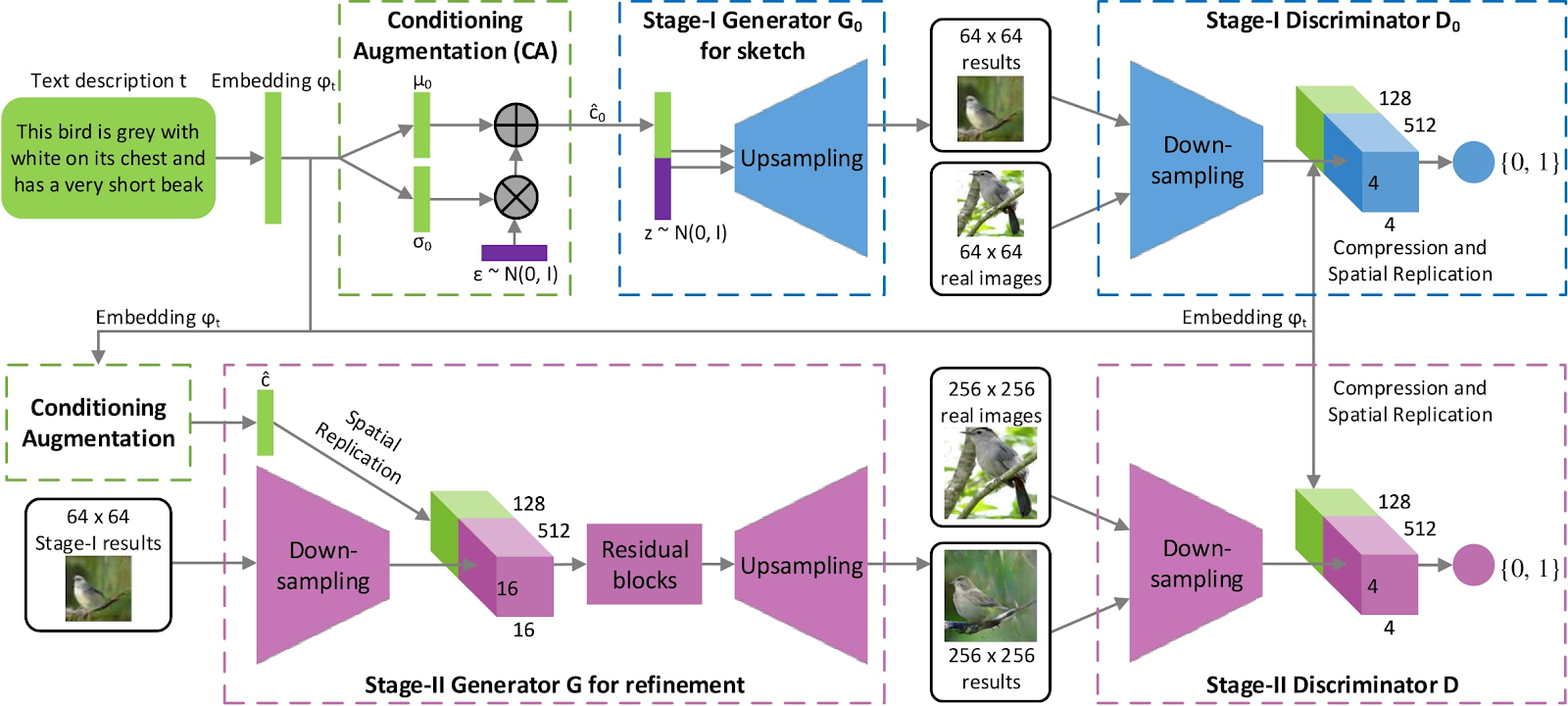
While solving this problem is possible with a regular GAN, output images can lack details and may be limited to lower resolutions. The StackGAN's two-stage architecture builds on the idea of cGANs to solve this, as the authors state in their paper: By conditioning on the Stage-I result and the text again, Stage-II GAN learns to capture the text information that is omitted by Stage-I GAN and draws more details for the object. The support of model distribution generated from a roughly aligned low-resolution image has better probability of intersecting with the support of image distribution. This is the underlying reason why Stage-II GAN is able to generate better high-resolution images.
To learn more about StackGAN, check out the authors' GitHub repo where they have provided both the model, as well as images for birds and flowers.
Summary: Use a StackGAN when you need to generate images from a completely different representation (e.g., from text-based descriptions).
Information Maximizing GAN
Similar to cGAN, an Information Maximizing GAN (InfoGAN) leverages additional information to provide more control over what is generated. In doing so it can learn to disentangle aspects of images such as hair styles, the presence of objects, or emotions, all through unsupervised training. This information can then be used to control certain aspects of the generated images. For example, given images of faces where some are wearing glasses, an InfoGAN could be trained to disentangle pixels for glasses, and then use that to generate new faces with glasses.
With an InfoGAN, one or more control variables are input along with the noise to the generator. The generator is trained using mutual information contained in an additional model called the auxiliary model, which shares the same weights as the discriminator but predicts the values of the control variables that were used to generate the image. This mutual information is acquired through observations on the images generated by the generator. Along with the discriminator, the auxiliary model trains the generator so that the InfoGAN learns to both generate/identify fake versus real images, and to capture salient properties of generated images, such that it learns to improve image generation. This architecture is summarized in the following diagram:
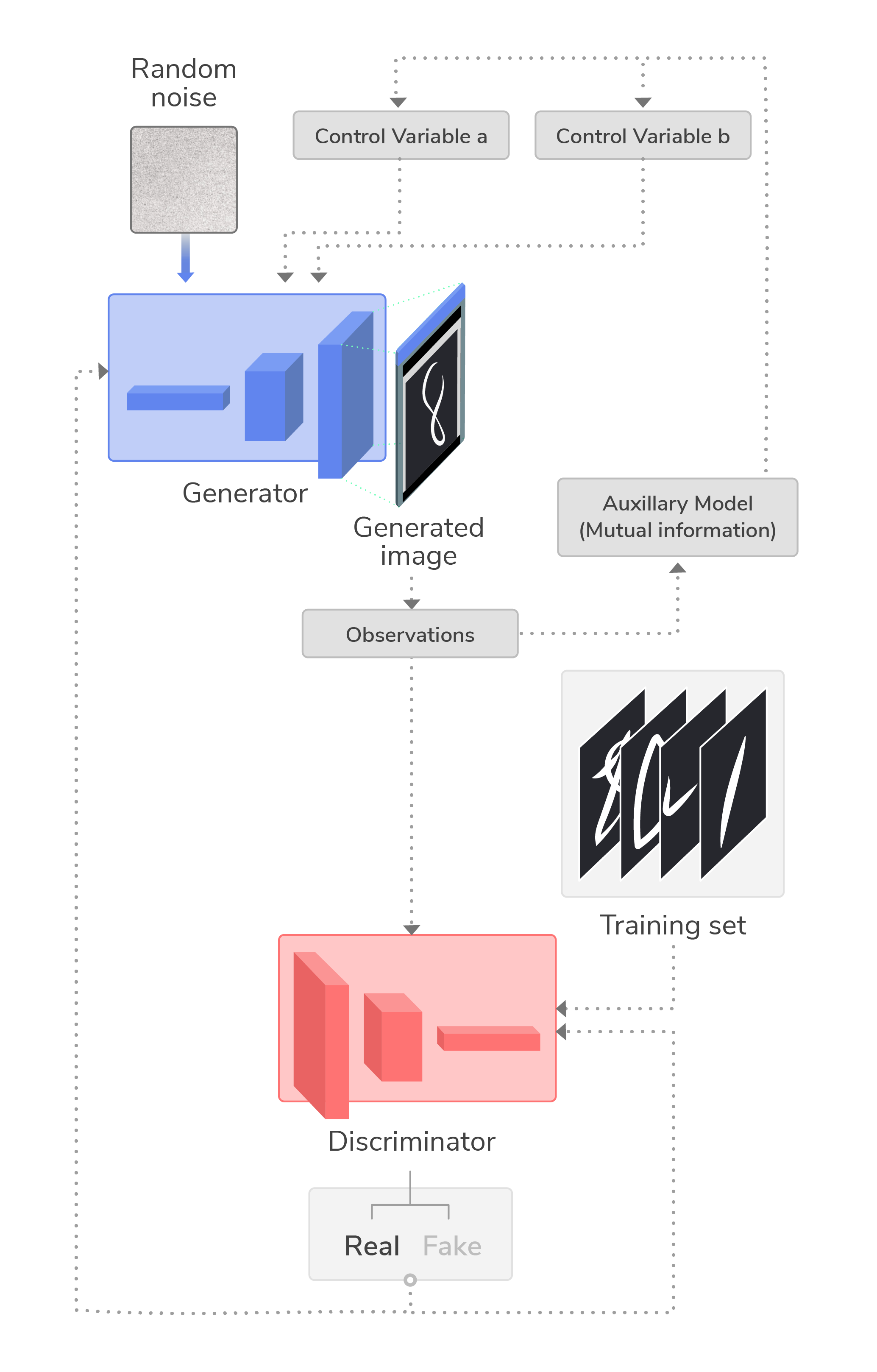
For more information about InfoGAN, check out this article.
Summary: Use an InfoGAN when you need to disentangle certain features of images for synthesis into newly-generated images.
Super Resolution GAN
The field of image enhancement is evolving to rely increasingly on machine learning (ML) algorithms rather than traditional statistical methods like bicubic interpolation. A Super Resolution GAN (SRGAN) is one such ML method that can upscale images to super high resolutions.
An SRGAN uses the adversarial nature of GANs, in combination with deep neural networks, to learn how to generate upscaled images (up to four times the resolution of the original). These resulting super resolution images have better accuracy and generally garner high mean opinion scores (MOS).
To train an SRGAN, a high-resolution image is first downsampled into a lower resolution image and input into a generator. The generator then tries to upsample that image into super resolution. The discriminator is used to compare the generated super-resolution image to the original high-resolution image. The GAN loss from the discriminator is then back propagated into both the discriminator and generator as shown here:
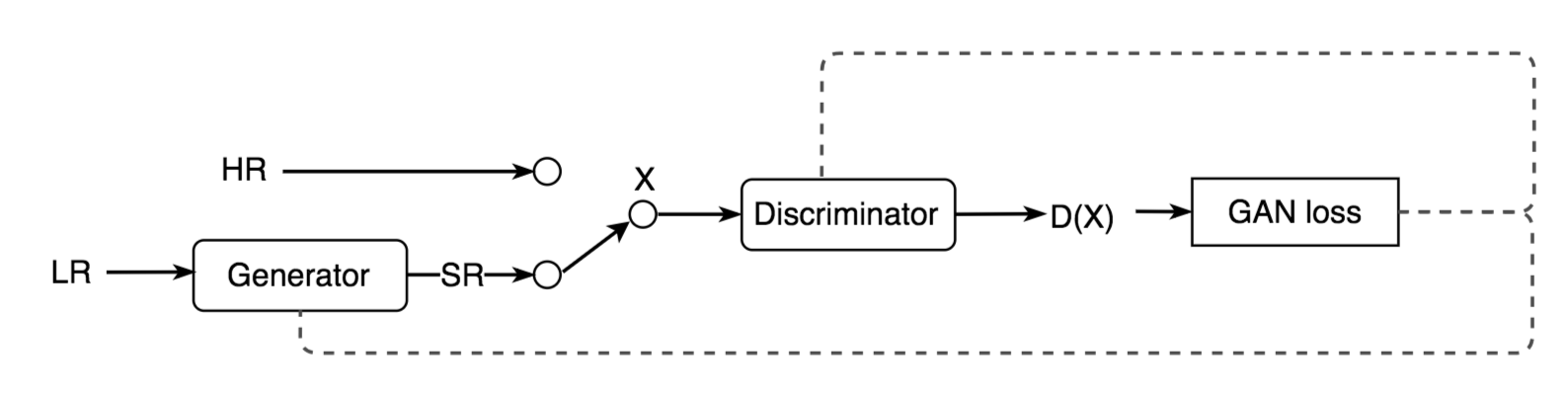
The generator uses a number of convolution neural networks (CNNs) and ResNets, along with batch-normalization layers, and ParametricReLU for the activation function. These first downsample the image before upsampling it to generate a super-resolution image. Similarly, the discriminator uses a series of CNNs along with dense layers, a Leaky ReLU, and a sigmoid activation to determine if an image is the original high-resolution image, or the super-resolution image output by the generator.
For more information about SRGANs check out this article.
Summary: Use an SRGAN when you need to upscale images while recovering or preserving fine-grain, high-fidelity details.
Pix2Pix
As we discussed in our blog Top Five Ways That Machine Learning is Being Used for Image Processing and Computer Vision, object segmentation is a method to partition groups of pixels from a digital image into segments which can then be labelled, located, and even tracked as objects in one or more images.
Segmentation can also be used to translate an input image to an output image for a variety of purposes such as synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing black and white images.
Segmentation can be accomplished using Pix2Pix, a type of cGAN for image-to-image translation, where a PatchGAN discriminator is first trained to classify whether generated images with these translations are real or fake, and then used to train a U-Net-based generator to produce increasingly believable translations. Using a cGAN means the model can be used for a wide variety of translations, whereas an unconditional GAN requires additional elements such as L2 regression to condition the output for different types of translations.

The following diagram shows how a discriminator in Pix2Pix is first trained in the case of colorizing a black and white image:
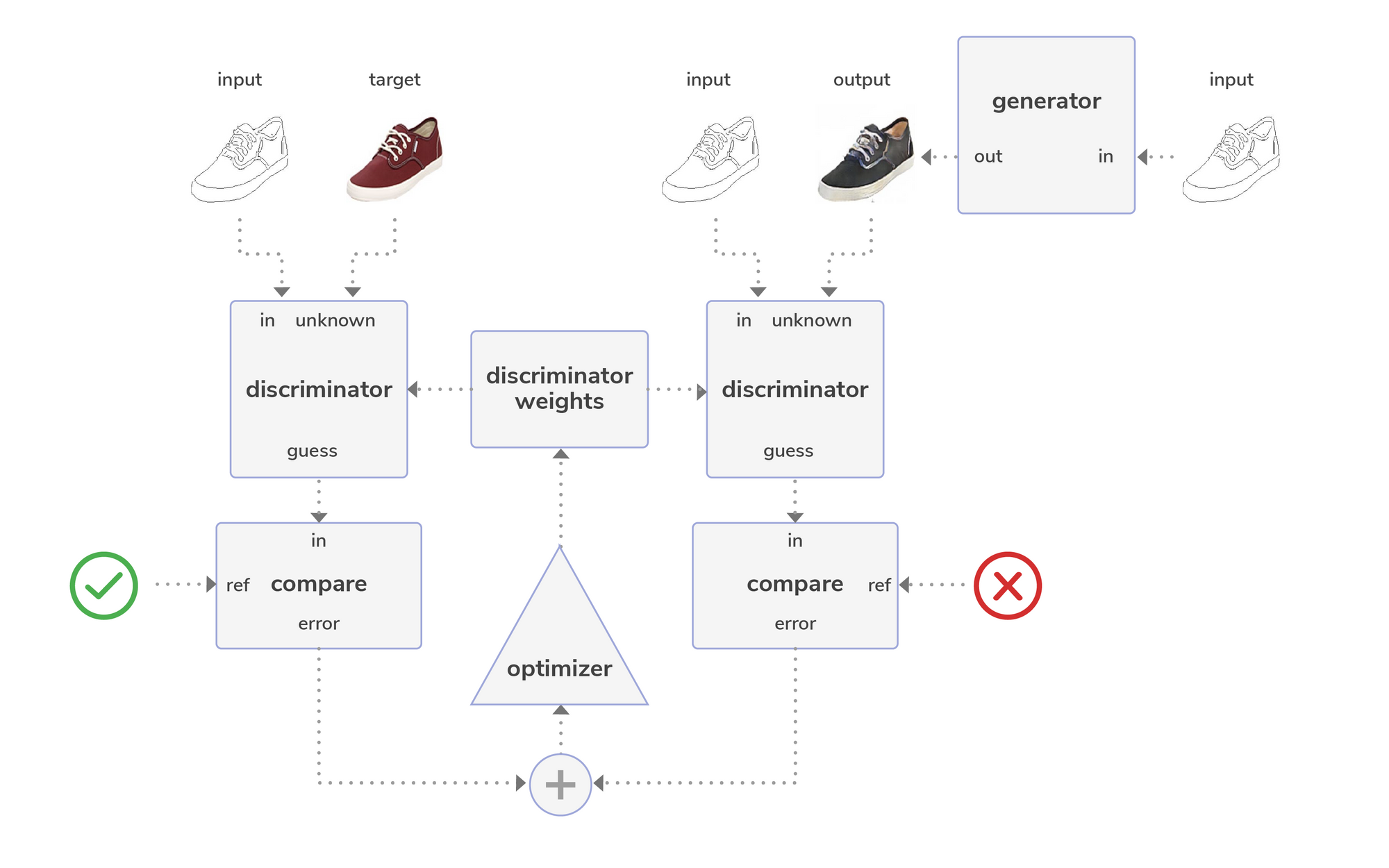
Here, a black and white image is provided as input to the generator which produces a colorized version (the output). The discriminator then performs two comparisons: the first compares the input to the target image (i.e., to training data representing ground truth) and the second compares the input to the output (i.e., generated image). An optimizer then adjusts the discriminator's weights based on the classification errors from both comparisons.
With the discriminator now trained, it can then be used to train the generator:
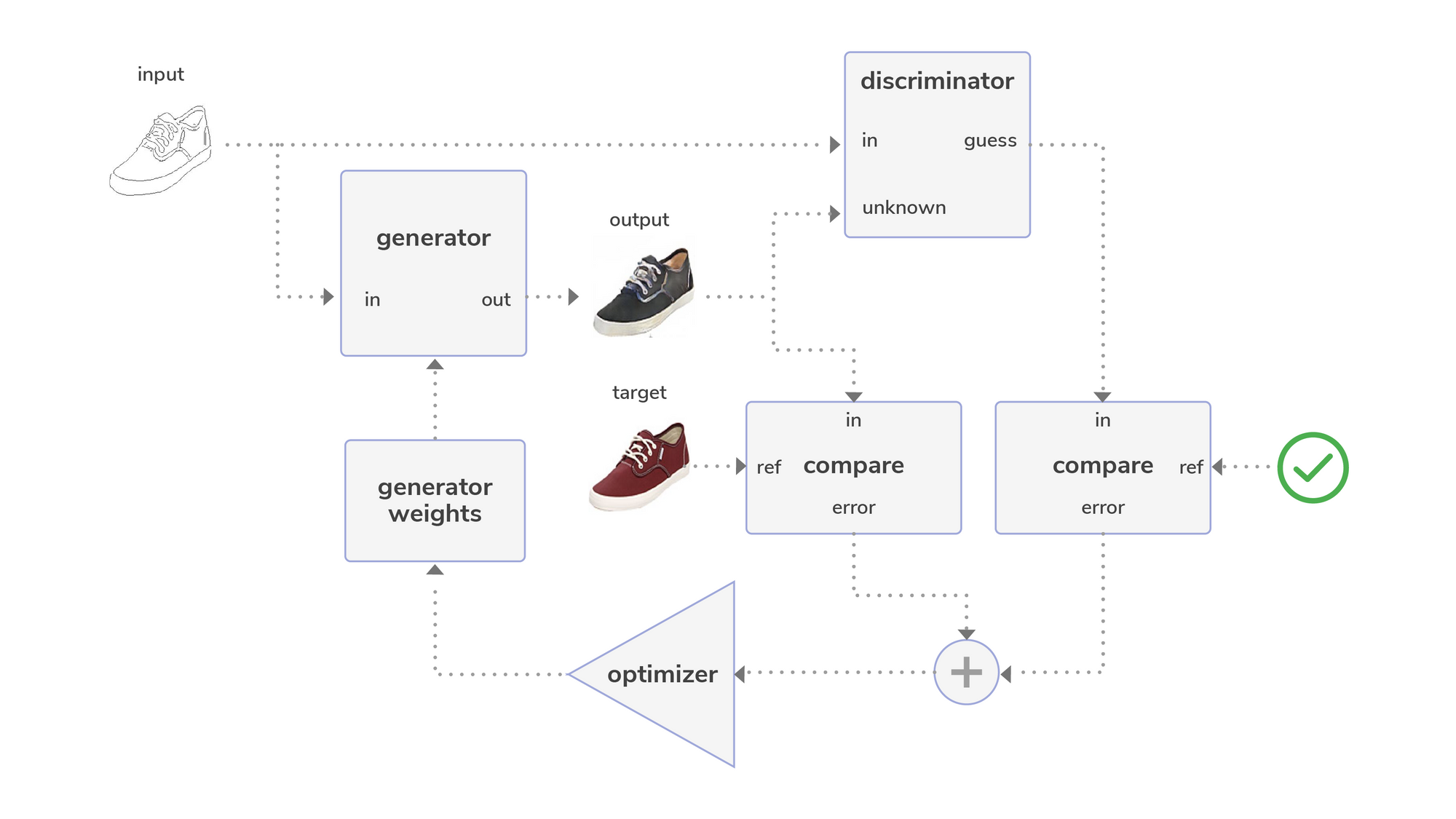
Here, the input image is fed into both the generator and discriminator. The (trained) discriminator compares the input image to the output from the generator, and the output to the target image. The optimizer then adjusts the weights of the generator until it's trained to the point where the generator is able to fool the discriminator the majority of the time.
For additional information about Pix2Pix, see this article. Also be sure to check out this GitHub repo.
Summary: Use a Pix2Pix GAN when you need to translate some aspect of a source image to a generated image.
Conclusion
GANs, and more specifically their discriminators and generators, can be architected in a variety of ways to solve a wide range of image processing problems. The following summary can help you choose which GAN might be right for your application:
- cGAN: controls (e.g., limits) the classifications that the GAN should train on.
- StackGAN: uses text-based descriptions as commands to create images.
- InfoGAN: disentangles specific aspects of images that you want to generate.
- SRGAN: upscales your images while maintaining fine-grained detail.
- pix2pix: segments and translates images (e.g., colorizes images).
What type of GANs do you currently work with?
PerceptiLabs' GAN component currently provides basic GAN functionality as shown in our GAN tutorial. As we continue to enhance PerceptiLabs, we'd love to get your input on what type of support for these different GAN architectures you'd like to see added. When you have a moment, please let us know via the General or Issues/Feedback channels of the PerceptiLabs forums.